
There seems to be a lot of discussion about software complexity, and although I think many people are talking about different stuff, here’s my take on it. We often compare writing software with other professional disciplines, like civil engineering and medicine, which allows us to pick at possible futures of writing software.
I believe writing software is hard, very hard, extremely hard. Probably one of the hardest thing to do. Any non trivial piece of code has an amazing amount of moving pieces. I bet the average software project is more complex than a car or a bridge. But how do we reconcile that with the fact that we have children programming and not children building cars or bridges?
Well, we do have children building cars and bridges, just that they are toy cars and toy bridges. Toy cars and bridges are very different from real cars and bridges. Toy software is not much different from real software. The path for going from toy to real in software, unlike in medicine, motor and civil engineering, is smooth. You don’t jump from building toy software into building real software, you just build better and bigger software until it’s real or professional.
That makes sense because software is abstract. Software is like ideas. There’s no jump between having toy ideas and having real ideas. If you don’t buy it, let’s do the analogy with math. There’s no jump between doing toy math and real math. You learn more math, more operations, more tools, but the sums and multiplication you learned when you were 5 years old are the same you use in civil engineering. There’s no toy sums vs real sums.
At some point in time, ages ago, math was primitive. A 12 year old could discover something new in math. We are at that period in the world of software writing. We are young and there’s not a lot out there. That’s why even though it’s extremely complex, a kid can still do something meaningful.
There’s something special about software. Even though it is abstract like math, it has a concrete impact, like civil engineering. So the 12 year old kid can do something new and it’s not just a piece of paper with a couple of numbers on it. It’s a real usable thing that other people can start, well, using. And that’s why I believe programming is so wonderful.
There’s another very important property of software that makes it so complex and still approachable. Imagine the world ages ago when 12 years old where doing math discoveries. Probably 99.9% were wrong in what they discovered as 99.9% of the software written by kids is wrong in the way it has bugs. But buggy software is still software and it’s still usable. Buggy math is wrong and should be discarded, buggy bridges kill people. Buggy software is a nuisance, but usable.
There’s some code in which only very smart and professional people put their hands on. Code written at NASA has something like 10 times more code to test it. Code put in a machine that can kill people, like a robot at a factory or a radiotherapy machine is written quite differently than the latest web toy or even the operating system you are using (last time I checked my analytics, nobody was using QNX to access this web site).

As software becomes more important in our lives, more of it has to be written rigorously. You can accept the latest web toy to crash, but you cannot accept your phone to crash. And then, the latest web toy becomes very important, like Twitter, and you cannot accept it to crash. The way code is written at NASA is more similar to the way a civil engineer makes a bridge: accounting for all possible variables.
It’s a real possibility that in 20 or 30 years all code will have to be written very rigorously. That means that you probably won’t be able to get a job working as a programmer in many, many places unless you have a proper degree, certification and license. I know it sounds crazy, but extrapolate about who was building bridges ages ago (anybody) and who are building them now (civil engineers) to who is building software now and who is going to be building software tomorrow.
For me, that sounds very depressing. I like the chaos of innovation that software is today. I probably couldn’t live in a rigorous software environment. One aspect that I haven’t analyzed is that, unlike civil engineers, software programmers will most likely always be able to build software by themselves, put it out there and be out of the loop of rigorous working. Anyone can build a bridge in their back-yard and nobody will use it, because it doesn’t stand a chance of being useful. But the back-yard of a programmer is the Internet. The only question is whether people will use that crapy web toy built by a 12-year old 20 years from now. I honestly hope so because that will keep the thriving environment of chaotic innovation that programming is today.
Reviewed by Daniel Magliola. Thank you! Broken bridge picture by Ghost V, rocket picture by SWP Moblog.
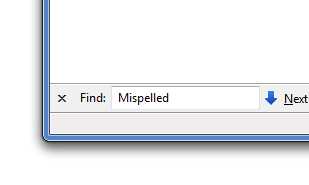 Web browsers, like Firefox or Chrome, are no longer document viewers, but application platforms. I’d like to see browsers start to implement search and replace. Of course not modifying the page, just replacing the matching strings in forms.
Web browsers, like Firefox or Chrome, are no longer document viewers, but application platforms. I’d like to see browsers start to implement search and replace. Of course not modifying the page, just replacing the matching strings in forms.

 I started using computers ages ago in Argentina. We only had US Qwerty keyboards back then and I’ve got used to them. The Spanish keyboards appeared later on and I never switched. I never understood what was the deal with those. I can type almost any character I want with a US Qwerty keyboard, even Spanish ones like á, é, í, ó, ú, ñ, ü. But furthermore, most characters used for programming are much harder to access in a Spanish keyboard.
I started using computers ages ago in Argentina. We only had US Qwerty keyboards back then and I’ve got used to them. The Spanish keyboards appeared later on and I never switched. I never understood what was the deal with those. I can type almost any character I want with a US Qwerty keyboard, even Spanish ones like á, é, í, ó, ú, ñ, ü. But furthermore, most characters used for programming are much harder to access in a Spanish keyboard.
 I’m not sure why ASP.NET MVC was shipped without a file input type for forms. Maybe it’ll come in MVC 2.0 or 3.0. Meanwhile, I created one. I spent two or three hours trying to figure out how to go from Object to IDictionary<String, Object> to follow the same ASP.NET MVC style where you have methods like:
I’m not sure why ASP.NET MVC was shipped without a file input type for forms. Maybe it’ll come in MVC 2.0 or 3.0. Meanwhile, I created one. I spent two or three hours trying to figure out how to go from Object to IDictionary<String, Object> to follow the same ASP.NET MVC style where you have methods like:
