150 years ago a great man was born. His name was Ludovic Lazarus Zamenhof and he was born to a world divided by language, a world of constant violence between polish, jews, russians, etc. All speaking different languages. He thought the problem of the world was that people could not understand each other and set himself the task of fixing it.
He invented what latter on became know as Esperanto. You can go to the Wikipedia and check the article on Esperanto and on Zamenhof to get a lot of encyclopedic information. If you want to actually taste or learn the language, my recommendation is to go to Lernu. And with that you can learn your first Esperanto word (if you don’t know any yet): lernu means learn, as in “you learn”. Lerni means to learn.
In this post I will tell you some things I find interesting about Esperanto.
Let’s go on with lerni. School is lernejo. See the relationship? lern – ej – o is school. Ej means a “a place for”, so lernejo is literarily a place to learn. There are other places like laborejo, which is the place to work. Laboro means work (think of ‘labor unions’).
Zamenhof thought about the task of creating the Esperanto dictionary and the task was so big he thought it was the end. Until he came up with the idea of allowing people to build words. My English-Esperanto, Esperanto-English dictionary is 75% for English, 25% for Esperanto. There are less words to learn in Esperanto.
Did you know the Wikipedia is available in Esperanto? If you go to wikipedia.org, you’ll see it among the languages with more than 100000 articles.

And if you go to the English wikipedia homepage, Esperanto is the only constructed language listed on the left column. Do you want to know something amazing? Vikipedio, the Esperanto Wikipedia is actually bigger than the Encyclopedia Britannica.
The legend goes that Zamenhof released his book about Esperanto, called La Unua Libro (the first book) and six months latter someone nocked at his door speaking Esperanto and asking to practice the language. Esperanto spread like wildfire, unlike any other constructed language.
 Today it is estimated that there are 2 million Esperantists in the world. If you consider that 122 years ago there was only one Esperanto speaker, it’s growing quite fast. I would expect its growth is accelerating but it’s very hard to know. No census asks about Esperanto. I know someone that made a informal survey asking for people that spoke Esperanto on the streets of Zürich and then actually asking questions in Esperanto and he got 3% positive response.
Today it is estimated that there are 2 million Esperantists in the world. If you consider that 122 years ago there was only one Esperanto speaker, it’s growing quite fast. I would expect its growth is accelerating but it’s very hard to know. No census asks about Esperanto. I know someone that made a informal survey asking for people that spoke Esperanto on the streets of Zürich and then actually asking questions in Esperanto and he got 3% positive response.
Those 2 million speakers are not concentrated in one location, they are spread through the world so you are very likely to find Esperanto-speakers everywhere if you know where to look.
There are even an estimate of 1000 native Esperanto speakers. Basically that happens when a family is formed by a man and a woman who only share Esperanto as a common language. Even if they don’t actively teach their children Esperanto, they learn to be able to understand their parents. I know a couple of people that speak it natively.
When talking about how many people speaks the language, it’s important to mention that Esperanto speakers were hunted by many totalitarian goverments. The Nazi government specially targeted them because Zamenhof was jewish and according to Hitler as expressed in his My Fight, Esperanto was the language to be used by the International Jewish Conspiracy to set a new world order.
In the Soviet Union Esperanto was embraced at first. Most socialists parties saw the potential for international communication and understanding. Joseph Stalin saw it as a way to spread the ideals of communism until they realized that it was a two way street, new ideas would come from outside, including capitalism, and denounced Esperanto as the language of spies. Imperial Japan didn’t like the language either.
In all those cases of totalitarism, Esperanto was forbidden and Esperantists hunted, exiled or even executed.
The first Esperanto congress was held in 1905, bringing 600 people together from across the world. since then it was held every year except during the world wars with an average of 2000 participants. When it was done in China it was the biggest gathering of foreign people ever to happen in China.
There’s a very practical reason to adopt Esperanto. Currently we waste a lot of resources pretending English is an adequate medium of international communication and in translation. Let me give you one example. In 1975 the World Health Organization denied the following requests:
- $ 148,200 to improve the health service in Bangladesh
- $ 83,000 to fight leprosy in Burma
- 50 cents per patient to cure trachoma, which causes blindness.
- $ 26,000 to improve hygiene in the Dominican Republic
All those requests denied. It seems the World Health Organization didn’t have much money. But that same year they approved Arabic and Chinese as working languages requiring lots of translations and increasing the expenses of the WHO by $ 5,000,000 per year. That’s right, 5 million dollars per year spent on translation when they couldn’t give 50 cents to cure trachoma.
Esperanto is probably the easiest to learn usable language out there. The Institute of Cybernetic Pedagogy at Paderborn compared how long it would take French speaking people to learn different languages to reach the same level:
- 2000 hours studying German
- 1500 hours studying English
- 1000 hours studying Italian
- 150 hours studying Esperanto
Yes, a tenth of the time it takes to learn English and less than that when compared to German. And something very interesting happens here. The third language you learn takes less effort than the second one.
If you want to learn another language, let’s say, German, it’ll take you less time to learn Esperanto and then learn German than to just learn German. Yes, you’ve read right. Less time to learn two languages than one.
That experiment was done by teaching one year of Esperanto and four of French to some students while five of French to others. The amount of time studying was the same but those that spoke Esperanto first reached a better French level. So even if you never utter a single Esperanto word out there, it makes economical sense to learn it first, before you learn another language.
Many said that Esperanto will never take off and they proceed to never learn it and accept a divided broken world. If you are among those, I’m sorry about your defeat. I’d rather hope and do my part and learn Esperanto. It’s not that hard.
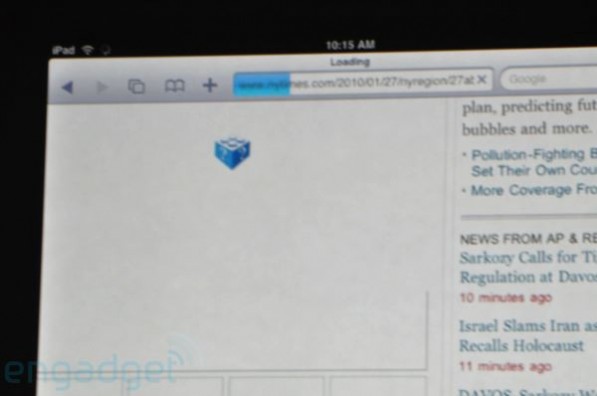 It seems iPad lack of Flash support is the debate of the moment. On one camp: “You can’t use the web without Flash”, on the other camp: “We don’t need no stinking Flash”. Although I do realize how a technology like Flash is sometimes needed, I’m more on the second camp. The less flash, the better.
It seems iPad lack of Flash support is the debate of the moment. On one camp: “You can’t use the web without Flash”, on the other camp: “We don’t need no stinking Flash”. Although I do realize how a technology like Flash is sometimes needed, I’m more on the second camp. The less flash, the better.
 I still haven’t found a good
I still haven’t found a good